
스토리지
- 블록 스토리지: I/O민감, 빠른 데이터의 처리, ≒ 직접 연결 스토리지(DAS), 스토리지 영역 네트워크(SAN)
- 파일 스토리지: 애플리케이션이 공유 파일에 엑세스하고 파일 시스템 필요, 성능 저하, NAS 서버에서 지원
- 객체 스토리지: 전체 데이터의 부분처리를 못하고 계층구조를 가지지 않음, 키값은 계층구조를 가짐 → 검색 비용↑
| 스토리지 유형 | 데이터 접근 방식 | 주요 장점 | 주요 단점 | AWS 서비스 |
| 블록 스토리지 | 블록 단위로 저장 | 고성능, 빠른 I/O | 네트워크 공유 어려움 | EBS, Instance Store |
| 파일 스토리지 | 파일 시스템 필요 | 여러 사용자 공유 가능 | 블록 스토리지보다 성능 낮음 | EFS, FSx |
| 객체 스토리지 | 객체 단위 저장 (키-값) | 확장성 높음, 저비용 | 일부 데이터 수정 불가, 검색 비용 높음 | S3, S3 Glacier |
S3
내구성이 뛰어난 객체 스토리지 솔루션
데이터를 버킷 내에 객체(파일+파일의 메타데이터) 단위로 저장
혁신의 가속성, 민첩성(버킷), 비용절감(종량제), 보안 강화(인증)
객체보호
S3 엑세스 제어
- 버킷 정책: JSON 형식으로 작성된 정책을 통해 버킷 및 객체에 대한 권한을 설정
- S3 퍼블릭 엑세스 차단: S3 데이터를 공개하지 않도록 강제 차단(모든 신규 버킷은 퍼블릭 액세스 차단)
- S3 Access Points: 여러 엔드포인트를 통해 다중 사용자/팀 접근 제어
개별 사용자/네트워크 별 맞춤 액세스 가능 - 서버측 암호화 키: 저장 시 자동 암호화 및 복호화 지원
AES-256, KMS 키, 고객 제공 키 옵션 제공
객체저장
- S3 스토리지 클래스: 다양한 데이터 보관 옵션 제공, 비용 최적화 가능
- S3 Intelligent-Tiering: 자동 계층 이동, 액세스 패턴 분석, 비용 절감
- S3 S3 Glacier 스토리지 클래스: 장기 보관용 저비용 스토리지로, 액세스 속도에 따라 다양한 옵션을 제공, 내구
- S3 버전 관리(versioning): 같은 객체의 여러 버전을 저장하는 기능, 실수로 파일을 덮어쓰거나 삭제했을 때 이전 버전으로 복원 가능, 실수 방지, 데이터 보호
- 수명 주기 정책: S3 객체의 저장 기간을 기반으로 자동 이동 또는 삭제를 설정
- S3 객체 복제
- Cross-Region Replication (CRR): 서로 다른 AWS 리전에 복제 → 데이터 이중화, DR(재해 복구)
- Same-Region Replication (SRR): 같은 리전 내의 다른 버킷으로 복제 → 데이터 백업, 규제 준수
S3 멀티파트 업로드: 대용량 객체를 관리 가능한 파트로 분할하여 일관되게 업로드 가능
업로드 시작 → 객체 파트 업로드 → 멀티파트 업로드 → S3에서 개별 부분으로 전체 객체 재생
S3 Transfer Acceleration: 전세계에 배포된 엣지 로케이션을 사용해 S3 버킷으로 데이터를 빠르고 쉽게 전송, 데이터는 최적화된 네트워크 경로를 통해 S3로 라우팅, AWS 서버와 클라이언트 애플리케이션 간 거리 줄임(AWS는 애플리케이션과 가장 가까운 엣지 로케이션을 통해 업로드와 다운로드를 자동으로 라우함)
S3 이벤트 알림: 버킷에서 특정 객체 이벤트가 발생할 때 알림, 객체 변경 사항을 확인하기 위해 서버 기반 폴링 인프라를 구축하거나 유지 관리할 필요 없음
S3 비용 관련 요인
- 스토리지 유형: 객체 저장 시 발생하는 GB당 비용
- 요청 및 검색: API 호출의 수
- 데이터 전송: 요청자의 로케이션, 데이터 전송 매체에 따라 다른 요금
- 관리 및 분석: 계정 버킷엣 활성화하는 스토리지 관리 및 분석에 대한 비
- 복제: 비쌈
- 버전 관리: 비쌈
공유 파일 시스템
여러 인스턴스가 동일한 스토리지 접근 가능, 여러 개의 서버(EC2 등)가 동시에 파일을 읽고 쓰는 파일 기반 스토리지
- EFS (Elastic File System): Linux 전용 NFS(Network File System) 기반의 완전관리형 파일 스토리지, 데이터가 여러 가용 영역(AZ)에 자동으로 복제되어 고가용성 및 내구성 제공
특징 설명 NFS 지원 EC2, 온프레미스에서 NFSv4.1 프로토콜로 접근 가능 자동 확장 필요할 때 용량이 자동 증가 고가용성 여러 AZ에 복제 비용 최적화 Standard & Infrequent Access(IA) 계층 제공 - FSx (Windows 및 Lustre 지원): SMB 프로토콜 또는 Lustre 기반의 완전관리형 파일 시스템
유형 특징 사용 사례 FSx for Windows SMB 지원, AD 통합 기업 파일 서버, Windows 애플리케이션 FSx for Lustre HPC, S3 연계 가능 머신러닝, 빅데이터 분석
데이터 마이그레이션 도구
마이그레이션: 데이터를 클라우드로 전송
1️⃣ 온라인
인터넷을 통해 AWS로 데이터를 전송하는 방식
- AWS Storage Gateway
- S3 File Gateway
- Tape Gateway
- Volume Gateway
- AWS DataSync
- AWS Transfer Family
| 서비스 | 설명 | 사용 사례 |
| AWS Storage Gateway | 온프레미스 데이터와 AWS 클라우드를 연결하는 하이브리드 스토리지 서비스 | 데이터 백업, 클라우드로의 점진적 마이그레이션 |
| S3 File Gateway | 온프레미스에서 S3를 파일 스토리지처럼 사용할 수 있도록 제공 | 파일 기반 백업, 데이터 아카이빙 |
| Tape Gateway | 가상 테이프 라이브러리를 통해 기존 백업 시스템을 AWS로 확장 | 기존 테이프 백업의 클라우드 이전 |
| Volume Gateway | 온프레미스 스토리지를 AWS 블록 스토리지로 확장 | 하이브리드 클라우드 스토리지 |
| AWS DataSync | 고속 데이터 전송 서비스 (NAS → S3, EFS, FSx 등) | 대량 데이터 마이그레이션 |
| AWS Transfer Family | SFTP, FTPS, FTP 프로토콜을 지원하는 파일 전송 서비스 | 기존 FTP 시스템을 AWS로 전환 |
2️⃣ 오프라인
물리적 디바이스를 사용하여 데이터를 AWS로 이동하는 방식
- AWS Snowball Edge
| 서비스 | 설명 | 사용 사례 |
| AWS Snowball Edge | 대량 데이터 전송을 위한 물리적 장치 | 10TB~100PB 규모 데이터 전송 |
데이터베이스 서비스
- 관계형 데이터베이스(SQL): 구조화된 데이터(테이블, 행, 열), SQL 사용, 고정된 스키마
데이터 무결성, ACID 트랜잭션(Atomicity, Consistency, Isolation, Durability) - 비관계형 데이터베이스(NoSQL): 스키마가 없는 유연한 데이터 구조(동적 스키마), JSON/Key-Value/Document/ Column-family/Graph 형식, 수평적 확장(대량 데이터 처리)
- 캐싱: 자주 조회되는 데이터를 메모리에 저장하여 빠르게 제공, 조회 속도 빠름
📌 SQL vs NoSQL
| SQL | NoSQL | |
| 데이터 구조 | 테이블, 행, 열 | Key-Value / Document |
| 확장성 | 제한적 (수직 확장) | 자동 확장 (수평 확장) |
| 쿼리 방식 | 복잡한 조인 및 트랜잭션 가능 | 빠른 조회, 단순 쿼리 |
1️⃣ 관계형 데이터베이스(SQL)
✅ RDS (Amazon Relational Database Service)
- AWS에서 제공하는 관리형 RDB 서비스
- 자동 백업, 모니터링, 유지보수 지원
- MySQL, PostgreSQL, MariaDB, SQL Server, Oracle 등을 지원
- 고가용성을 위해 Multi-AZ 배포 가능 → 여러 AZ에 걸쳐 자동 장애 조치 제공
- 읽기 전용 복제본(Read Replica) 제공 → 성능 확장 가능
✅ Aurora (Amazon Aurora)
- RDS의 고성능 버전 (MySQL 및 PostgreSQL 호환)
- RDS 대비 3~5배 빠름
- 6개 복제본이 자동으로 여러 AZ에 저장 → 높은 가용성
- 자동 확장 지원 (최대 128TB까지 증가 가능)
- Aurora Serverless 제공 → 서버리스 환경에서 필요할 때만 DB 인스턴스를 실행
📌 RDS vs Aurora
| RDS | Aurora | |
| 성능 | 일반 | RDS보다 3~5배 빠름 |
| 확장성 | 수동 조정 필요 | 자동 확장 |
| 가용성 | Multi-AZ 지원 | 6개 복제본 자동 저장 |
| 비용 | 인스턴스 기반 | 사용량 기반(Aurora Serverless) |
2️⃣ 비관계형 데이터베이스(NoSQL)
✅ DynamoDB
- AWS에서 제공하는 완전관리형 Key-Value 및 Document 기반 NoSQL 데이터베이스
- 수평적 확장 지원 → 초당 수백만 개의 요청 처리 가능
- 서버리스 (프로비저닝 필요 없음)
- 자동 백업 및 복구 지원
- 일관성 모드 선택 가능: 강력한 일관성 vs 최종적 일관성
- 글로벌 테이블: 테이블이 서로 다른 AWS 리전에 상주할 수 있음
3️⃣ 인메모리 데이터베이스 & 캐싱
✅ Elasticache (Redis & Memcached)
- AWS에서 제공하는 완전관리형 인메모리 캐싱 서비스
- Redis 또는 Memcached 엔진을 사용 가능
- 초당 수백만 개의 요청 처리 가능 → 빠른 응답 속도
- DynamoDB와 함께 사용 가능 (DAX)
| Redis | Memcached | |
| 데이터 구조 | Key-Value, 리스트, 해시, 정렬된 집합 | 단순 Key-Value |
| 지속성 | 데이터 영구 저장 가능 | 휘발성 (재부팅 시 데이터 손실) |
| 기능 | Pub/Sub, Lua 스크립트 | 단순 캐싱 용도 |
| 사용 사례 | 세션 관리, 메시징 | 분산 캐시 |
캐시 항목
- 속도와 비용: 쿼리 속도가 느리고 비용이 많이 드는 데이터
- 데이터 및 엑세스 패턴: 자주 엑세스하는 데이터
- 캐시 유효성: 비교적 정적 상태로 유지되는 정보
✅ 캐싱 전략: 데이터 조회 속도를 높이기 위해 자주 사용되는 데이터를 메모리에 저장하는 기법
- 레이지 로딩(Lazy Loading, 지연 로딩): 캐시를 업데이트하지 않고 데이터베이스를 업데이트, 캐시 미스↑
- 라이트 스루(Write-through): 데이터베이스에 엑세스할 때마다 캐시에 라이트 스루를 수행, 캐시 미스↓
📌 레이지 로딩 vs 라이트 스루
| 전략 | 캐시 미스 | 장점 | 단점 | 성능 | 데이터 최신성 |
| 레이지 로딩 | 발생↑ | 캐시에 불필요한 데이터가 저장되지 않음 → 메모리 절약 | 첫 번째 요청이 항상 느림 (캐시 미스가 발생할 경우 DB에 접근) | 메모리 절약, 첫 번째 요청 느림 | DB와 캐시 동기화 필요 |
| 라이트 스루 | 발생↓ | 최신 데이터를 항상 캐시에 유지 가능 | 쓰기 성능이 저하될 수 있으며, 추가적인 스토리지 비용이 발생 | DB와 함께 캐시 업데이트 | 데이터 일관성 유지 |
캐시 관리
- 캐시 유효성: 캐시는 DB와 다르게 갱신되지 않으므로, 데이터가 최신 상태인지 확인, 캐시 데이터를 삭제하거나 갱신
- TTL (Time-To-Live): 특정 시간이 지나면 캐시 데이터를 자동으로 삭제
- Write-through: DB 업데이트 시 캐시도 동시에 갱신
- Manual Invalidation: 애플리케이션이 직접 캐시를 삭제
- 메모리 관리: LRU(Least Recently Used) 정책을 사용하여 오래된 데이터를 삭제
✅ 인메모리 캐싱 서비스: 완전 관리형 서비스 → 캐시 장애 시 자동 복
- ElastiCache: 고속 데이터 조회 및 DB 부하 감소
- DynamoDB Accelerator(DAX): 100배 빠른 읽기 성능 제공, 강력한 일관성 지원
📌 ElastiCache vs DAX 비교
| ElastiCache | DAX | |
| 대상 | 모든 DB 및 애플리케이션 | DynamoDB 전용 |
| 속도 | 밀리초 단위 응답 | 마이크로초 단위 응답 |
| 일관성 | 기본적으로 최종적 일관성 | 강력한 일관성 지원 |
| 관리 | 관리 필요 | 완전 관리형 |
✅ 데이터베이스 마이그레이션 도구
- AWS Database Migration Service(DMS): 운영 중인 데이터베이스를 다운타임 없이 AWS로 마이그레이션, 온프레미스/클라우드 간 데이터베이스 이전, CDC(Change Data Capture) 기능 제공 → 실시간 동기화 가능
- AWS Schema Conversion Tool(SCT): 이종 DB 마이그레이션을 위한 스키마 변환 도구, GUI 기반
📌 AWS DMS vs AWS SCT 비교
| AWS DMS | AWS SCT | |
| 기능 | 실시간 데이터 마이그레이션 | DB 스키마 변환 |
| 사용 대상 | 동일한 DB 엔진 or 다른 DB 엔진 | 서로 다른 DB 엔진 |
| 변환 요소 | 데이터 이동 및 동기화 | 테이블, 인덱스, 프로시저 변환 |
| 예시 | MySQL → Aurora | Oracle → PostgreSQL |
실습3)
Amazon VPC 인프라에 데이터베이스 계층 생성
- Amazon RDS 데이터베이스 생성

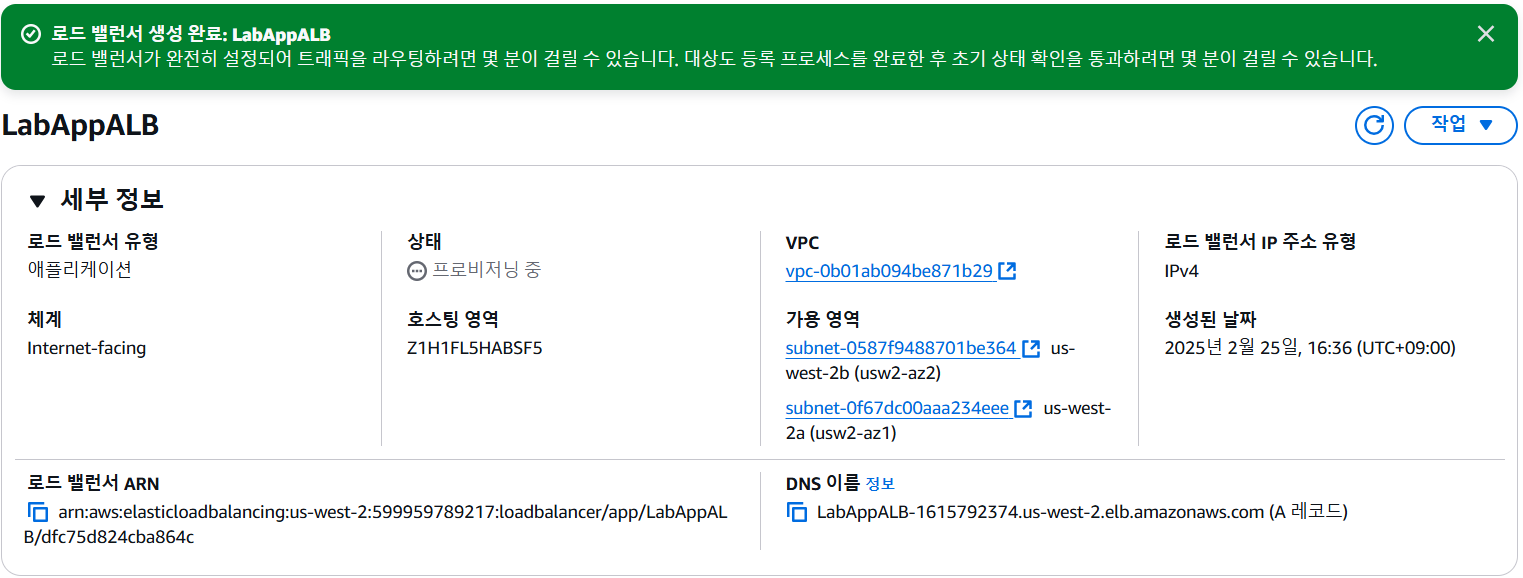
Application Load Balancer 생성 및 구성
- 대상 그룹 생성
- Application Load Balancer 생성
콘솔을 통해 Amazon RDS DB 인스턴스 메타데이터 검토

애플리케이션의 데이터베이스 연결 테스트
- 데이터베이스 연결을 위해 설정값 추가
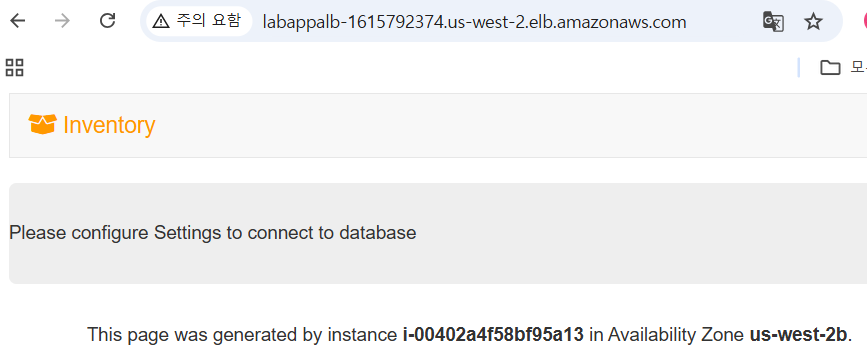
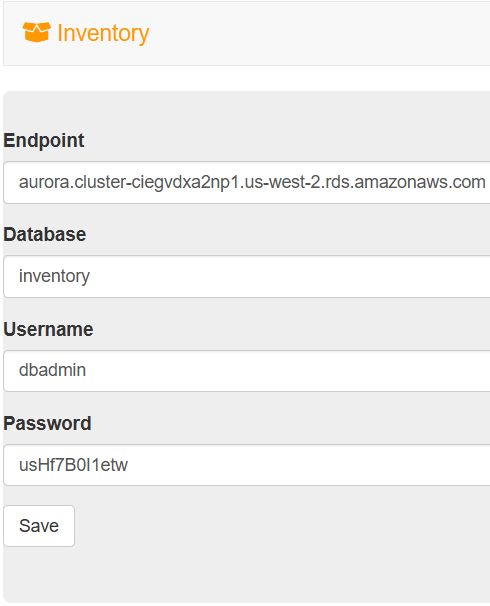
- 애플리케이션이 데이터베이스에 연결되어, 기본 데이터를 가져오고 정보를 화면에 나타냄
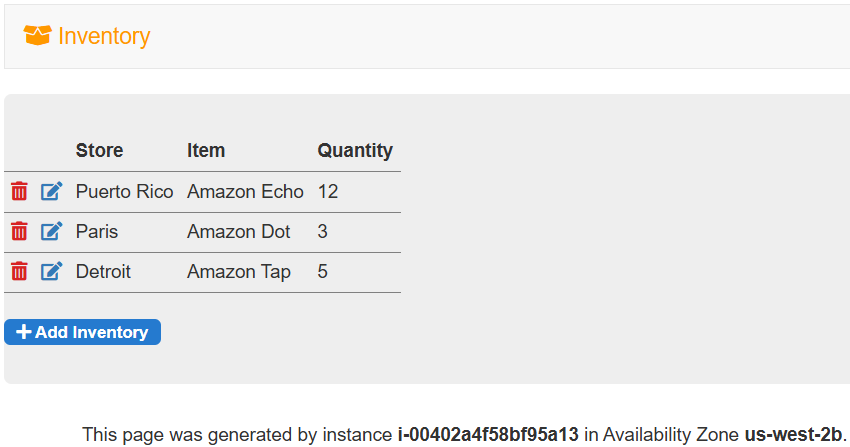
RDS 선택에서 이용하는 EC2 instance의 비용의 구매 옵션은 무엇일까?
→ 온디맨드(RI, Saving Plans), 스팟은 불가능
RDS 사용시 감안해야 하는 불편함 및 단점은 무엇일까?
→ 요구사항에 충족되지 않는 부분이 생김
- RPO, 복구와 관련해 백업 플랜을 회사 기준에 맞추고 싶지만, Backup retention period가 제약적이라 snapshot을 사용해야 하는 경우가 생길 수 있음
- 자동 업그레이드와 관련된 버전 관리 옵션 등
모니터링 및 크기 조정
모니터링: 운영 상태, 애플리케이션 성능, 리소스 사용률, 보안 감사
주요 모니터링 도구
- CloudWatch: AWS 인프라 및 애플리케이션을 실시간 모니터링, 지표(metric) 기반
- CloudWatch Logs: 로그 수집 및 분석
- AWS CloudTrail: AWS 계정 내 API 활동 기록(계정 사용 기록, 루트 로그인 실패 캡처 등)
- VPC 흐름 로그: 네트워크 트래픽 모니터링
- 사용자 정의 로그
- CloudWatch 경보(Alarms): 특정 임계값 초과 시 알림 또는 자동 조치 수행
- OK: 정상 상태
- ALARM: 임계값 초과 (문제 발생)
- INSUFFICIENT DATA: 충분한 데이터가 없음 (새로운 인스턴스 시작 등)
- EventBridge: 이벤트 기반 자동화 서비스, 계정 리소스 및 지원되는 서드 파티 관리 서비스의 데이터를 기반으로 작업을 간접적으로 호출할 수 있는 서비스
✅ CloudWatch 경보 생성 흐름
- CloudWatch 지표 수집 (예: EC2의 CPU 사용량)
- 임계값 설정 (예: CPU 사용률 80% 초과)
- 임계값 초과 시 수행할 작업 지정 (예: SNS 알림 또는 Auto Scaling)
📌 주요 모니터링 도구
| 개념 | 설명 | 주요 특징 |
| CloudWatch | AWS 모니터링 서비스 | 지표 기반, 로그 분석, 경보 설정 가능 |
| CloudWatch Logs | 로그 저장 및 분석 | API 로그, 네트워크 로그, 사용자 로그 |
| AWS CloudTrail | API 활동 기록 | 보안 감사, 규정 준수 |
| VPC 흐름 로그 | 네트워크 트래픽 로그 | 보안 및 성능 분석 |
| CloudWatch 경보 | 특정 조건 초과 시 알림/조치 | SNS 알림, Auto Scaling 연동 가능 |
| EventBridge | 이벤트 기반 자동화 | AWS 서비스 간 이벤트 트리거 |
로드 밸런싱(Load Balancing)
다수의 서버에 트래픽을 분산하여 성능을 최적화하고, 가용성을 높이며, 장애를 방지
ELB(Elastic Load Balancer)
- ALB (Application Load Balancer): 7계층(L7)에서 작동, HTTP/HTTPS 트래픽을 분산
- NLB (Network Load Balancer): 4계층(L4)에서 작동, 높은 성능과 낮은 지연 시간이 필요한 TCP/UDP 트래픽을 처리
- CLB (Classic Load Balancer): L4/L7에서 작동하지만, ALB/NLB보다 기능이 제한적 (레거시)
자동 규모 조정(Auto Scaling)
EC2 인스턴스를 자동으로 확장(Scale-out)하거나 축소(Scale-in)하여 리소스 사용률을 최적화하고 비용을 절감
Auto Scaling 구성 요소
- 시작 템플릿: EC2 인스턴스의 AMI, 인스턴스 유형, 키 페어, 보안 그룹 등 기본 설정 정의, ASG 인스턴스 생성시 사용
- EC2 Auto Scaling Group(ASG): EC2 인스턴스들의 논리적 그룹, 정의된 인스턴스 수에 따라 자동 조정
- 규모 조정 정책: 인스턴스를 증가/감소시키는 조건
- 동적 조정 (Dynamic Scaling): CloudWatch 지표 기반
- 예측 조정 (Predictive Scaling): 과거 트래픽 패턴을 학습하여 미리 확장
💡 ELB와 Auto Scaling을 함께 사용하면 트래픽 분산 + 자동 확장을 통해 고가용성과 비용 절감을 극대화
실습4)
Amazon VPC에서 고가용성 구성
시작 템플릿 생성

Auto Scaling 그룹 생성

애플리케이션 테스트
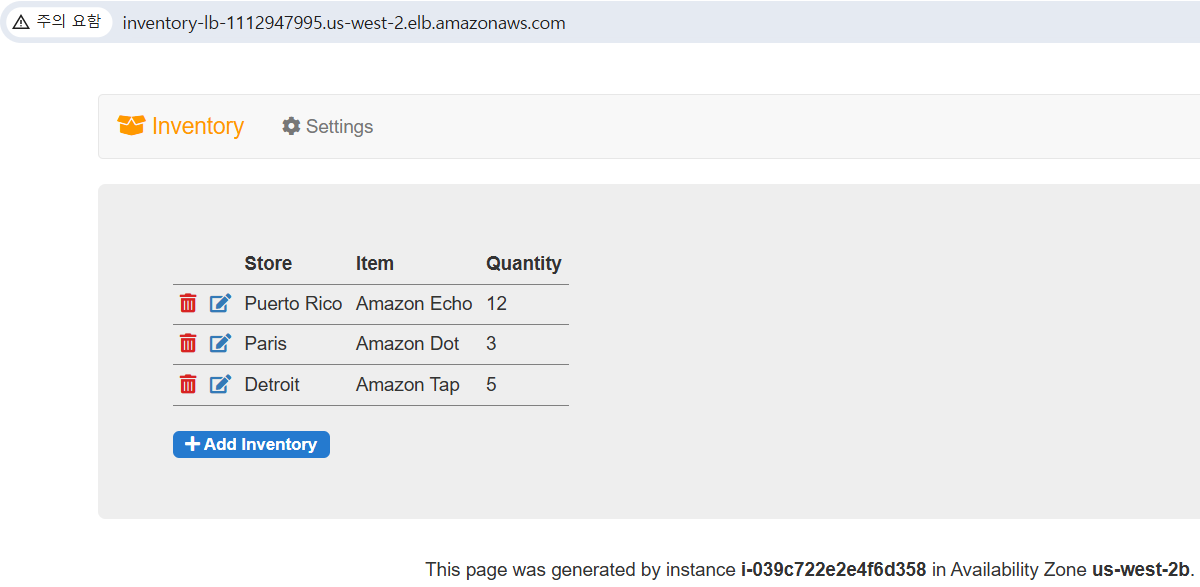
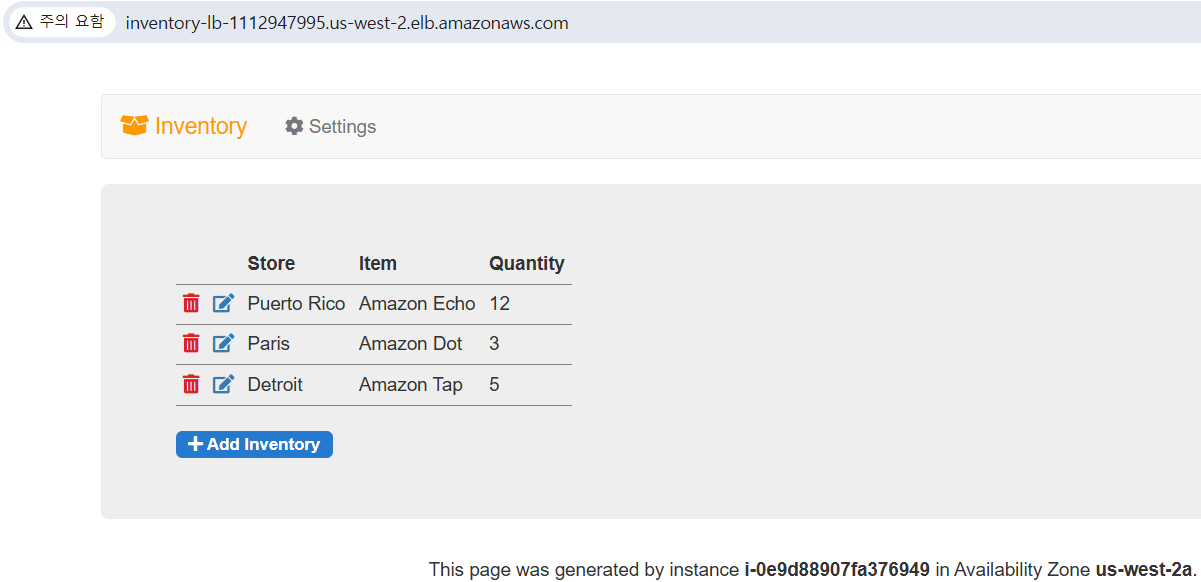
- 퍼블릭 서브넷에 있는 Application Load Balancer로 요청을 전송(퍼블릭 서브넷: 인터넷에 연결)
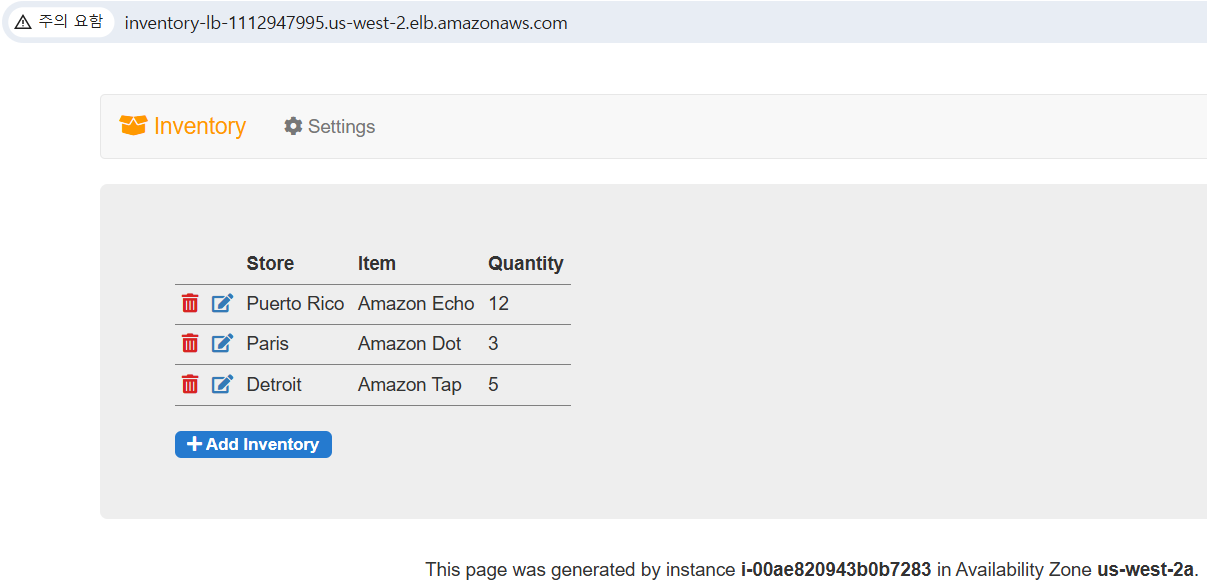
- Application Load Balancer가 프라이빗 서브넷에 있는 EC2 인스턴스 중 하나를 선택해 요청을 전달.
- EC2 인스턴스가 Application Load Balancer에 웹 페이지를 반환하고, Application Load Balancer가 웹 페이지를 웹 브라우저에 반환
웹 애플리케이션 흐름
인터넷 ↔ 퍼블릭서브넷(ALB) ↔ 프라이빗 서브넷(앱서버)
# Amazon EC2 Auto Scaling이 가용 영역 2개에서 새 Inventory-App 인스턴스 2개를 시작
# Auto Scaling 그룹은 장애가 발생하는 경우 애플리케이션의 고가용성을 유지
애플리케이션 티어의 고가용성 테스트
- Amazon EC2 Auto Scaling이 관리하는 Inventory-App 인스턴스 중 하나를 종료하여 장애를 시뮬레이션
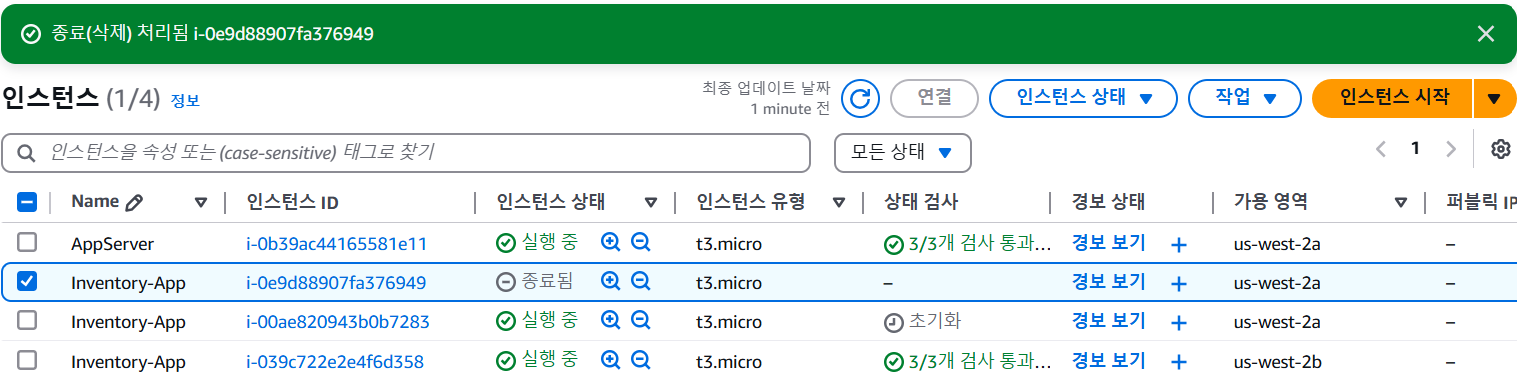
- Amazon EC2 Auto Scaling이 자동으로 대체 인스턴스를 시작
2개의 인스턴스가 계속 실행되도록 Amazon EC2 Auto Scaling을 구성했기 때문

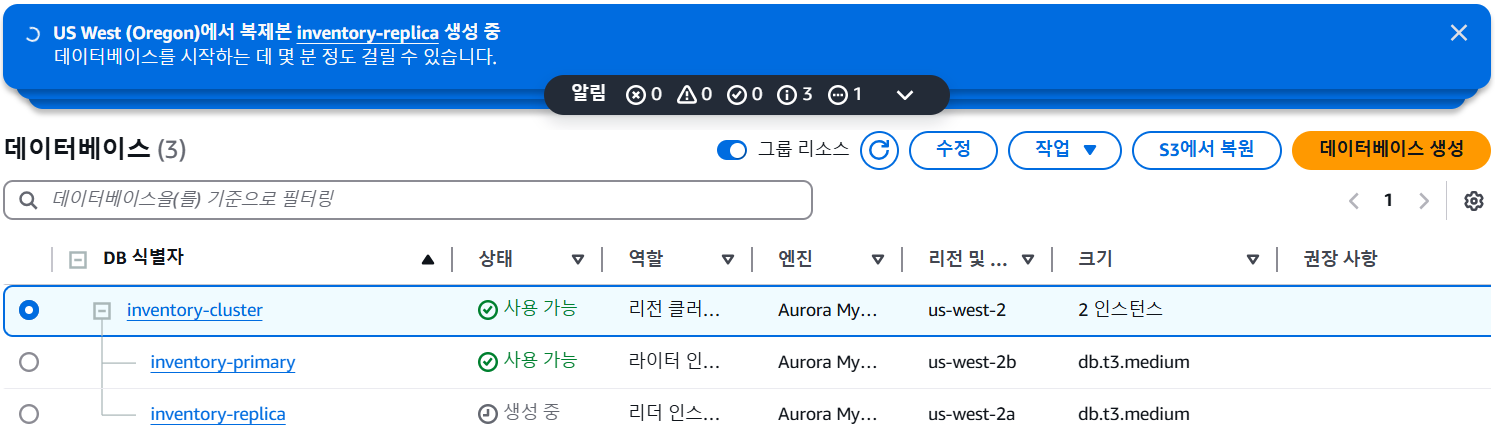
데이터베이스 티어의 고가용성 구성
- 프라이머리 인스턴스와 다른 가용 영역에 복제본 생성
NAT 게이트웨이가 고가용성을 제공하도록 설정
- 두 번째 NAT 게이트웨이 생성
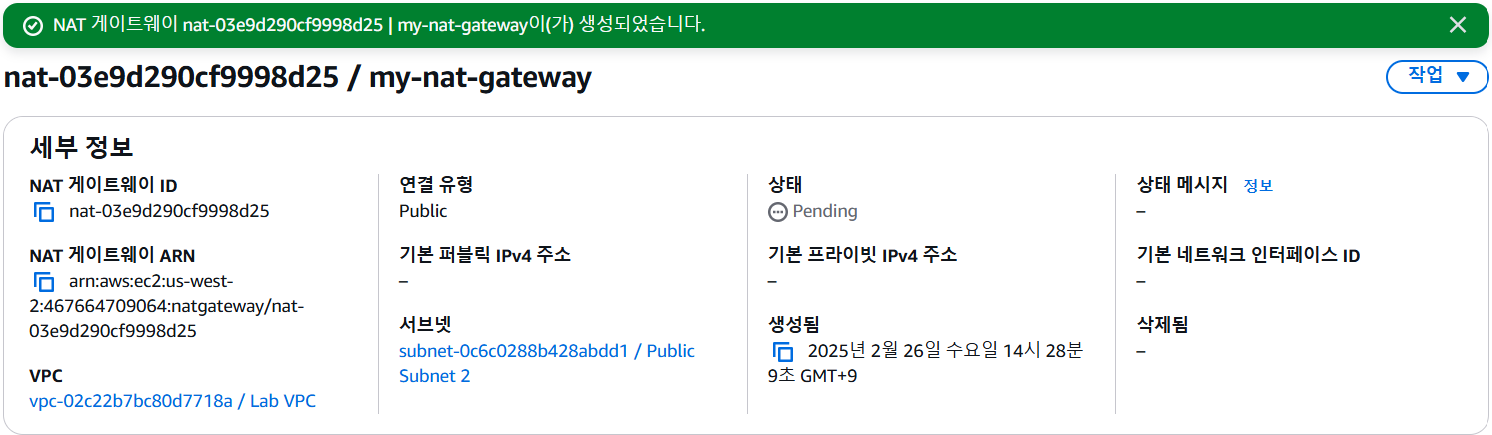
- 라우팅 테이블 생성 후 NAT 게이트웨이를 통해 인터넷 바운드 트래픽을 라우팅하도록 구성
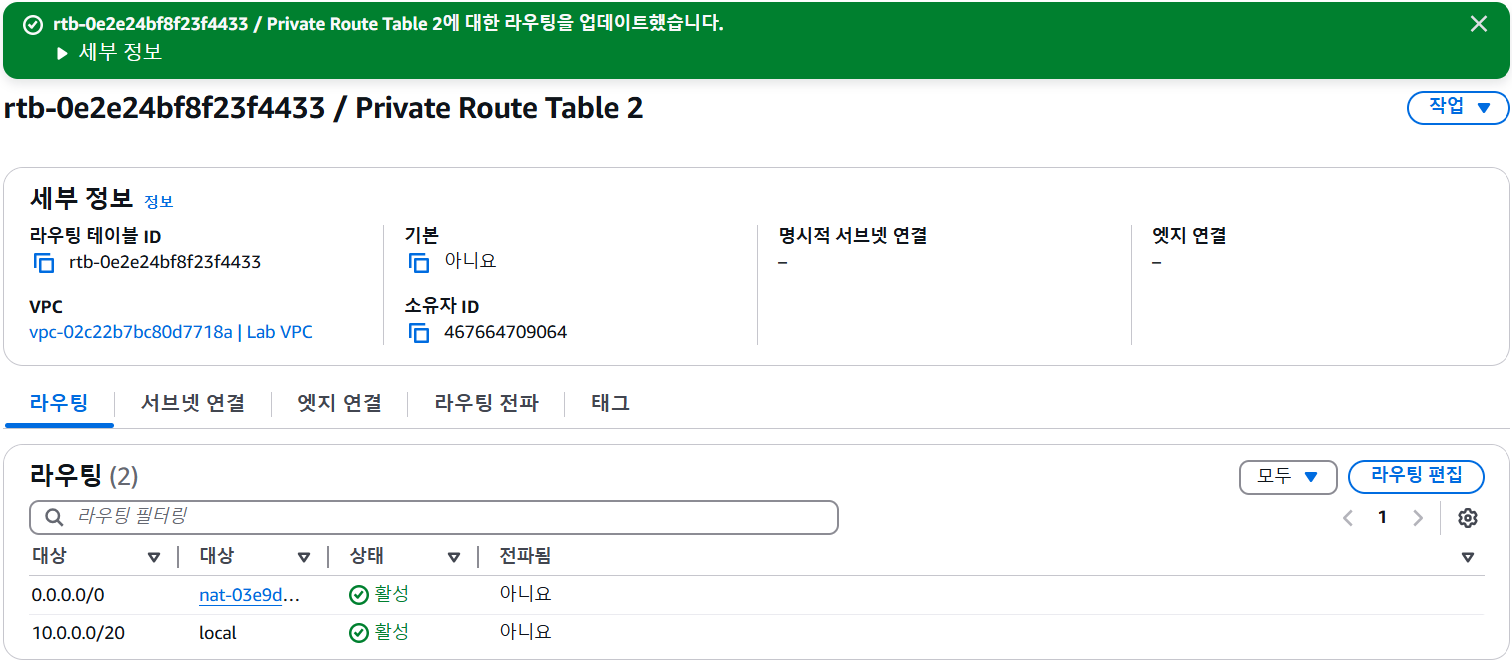
- 프라이빗 서브넷 2 라우팅

Aurora 데이터베이스 장애 조치 적용
- 데이터베이스가 장애 조치를 완료하고 고가용성을 제공하도록 설정되었음을 확인
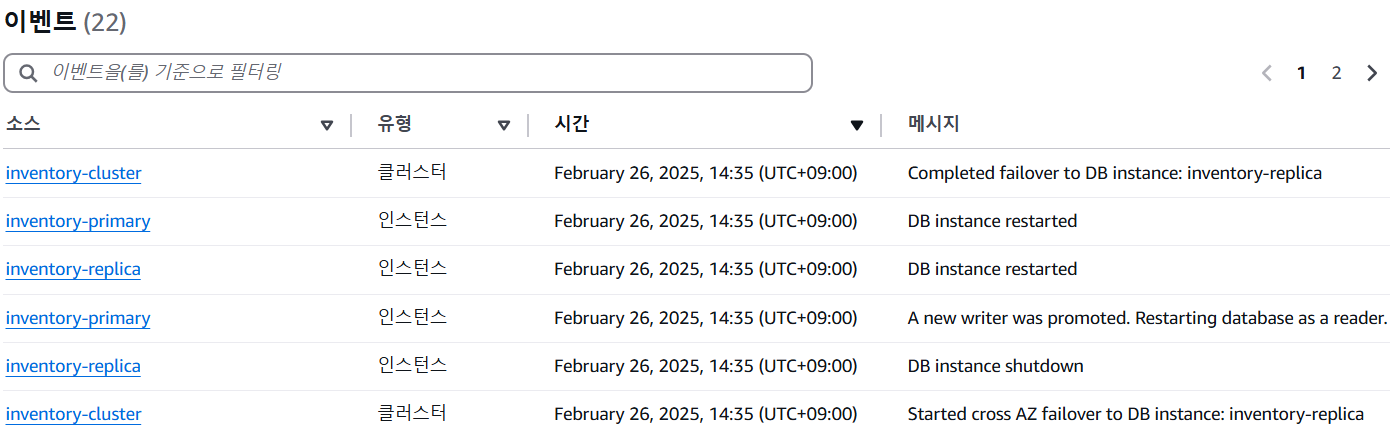
장애 조치 발생 → 로그 검토 → 읽기 전용 복제본 인스턴스 종료 → Writer로 승격 후 재부팅 → 읽기 전용 복제본 재부팅 완료 → inventory-primary가 재부팅
'AWS 공인교육' 카테고리의 다른 글
| 41일차) 2025-02-26(공인교육6. Architecting on AWS) (0) | 2025.02.24 |
|---|---|
| 39일차) 2025-02-24(공인교육4. Architecting on AWS) (0) | 2025.02.24 |
| 16일차) 2025-01-17(공인교육3. AWS Technical Essentials) (1) | 2025.01.17 |